Overview
At Milliman, we work with our clients—from the large global underwriters to small insurance companies, from well-known self-insured corporations to public entity risk pools, from third party administrators to non-insurance entities—and help them uncover valuable information hidden in their data, allowing them to take action on key business insight.
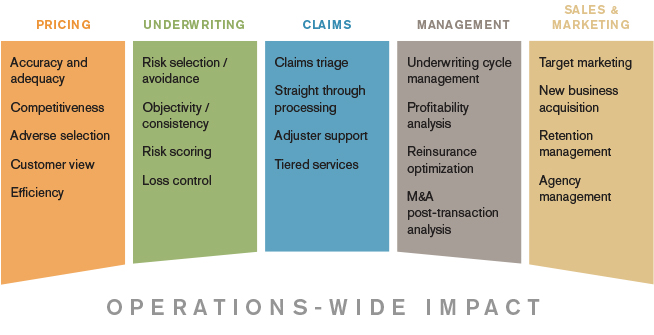
Our predictive analytic solutions combine traditional statistical methods with machine learning technology and innovative data mining techniques. These advanced modeling methods do not require you to specify the predictors—they actually discover them by analyzing the interaction of multiple, nonlinear variables of risks in your portfolio, identifying specific risk factor combinations that are predictive of future outcomes. Milliman’s predictive analytics solutions provide clear, actionable results to help you gain a competitive advantage by:
- Selecting and pricing your business with greater precision
- Reducing loss ratios and improving operating results
- Targeting the best opportunities for future growth and profitability
- Providing clear insight into expected claim outcomes
- Optimizing effectiveness and efficiency of key personnel and resources
- Protecting your margins in adverse underwriting and investment environments
- Identifying and projecting operating costs
Powerful predictive analytics technology is a “profit engine” enabling you to uncover hidden opportunities and challenges within your business.