Artificial intelligence (AI) has generated significant buzz lately and its ubiquity in our lives is increasing through the likes of Siri, Alexa, and AI-powered search engines. With OpenAI’s release of ChatGPT for public access on November 30, 2022, the application quickly accumulated 1 million users within a week of its launch, an unprecedented pace for a consumer application.1 In the following months, some of the world’s largest corporations have come forward to announce multimillion-dollar investments in AI, citing opportunities to reduce costs and increase efficiency.
With the increasing popularity and use of AI, it is important to understand how this sophisticated technology operates, where it excels, and where it may fall short. This paper dives into the root of recent AI advances—large language models (LLMs)—and how these models are trained to produce accurate results. Through this process, we will walk through several use cases pertaining to the insurance industry that shed light on what skills are needed when using LLMs, the type of results such models can produce, and how to mitigate risks. As with any innovative technology, analyzing potential issues and risks associated with its use is vital. We will discuss some of the ethical and safety concerns associated with AI as a point of consideration when utilizing this technology.
What is a language model?
A language model uses machine learning to predict the next word that is most probable in a sentence, based on the previous entries.
Modern language models are usually based on neural network (NN) models. Figure 1 illustrates a common way to visualize neural networks. In this plot, the circles are called neurons, and each column of the neurons is called a layer. Each line represents a weight factor that would be learned by the model over time. Each neuron also has a value, and these values are not parameters of the model but calculated and updated over time. For example, if we look at the first neuron in the second column, there are lines connecting it to every neuron in the input layer. That means the value of this neuron would be calculated as a function of all input values. Then the value of this neuron will be used by neurons in the next layer.
Figure 1: Neural Network Architecture
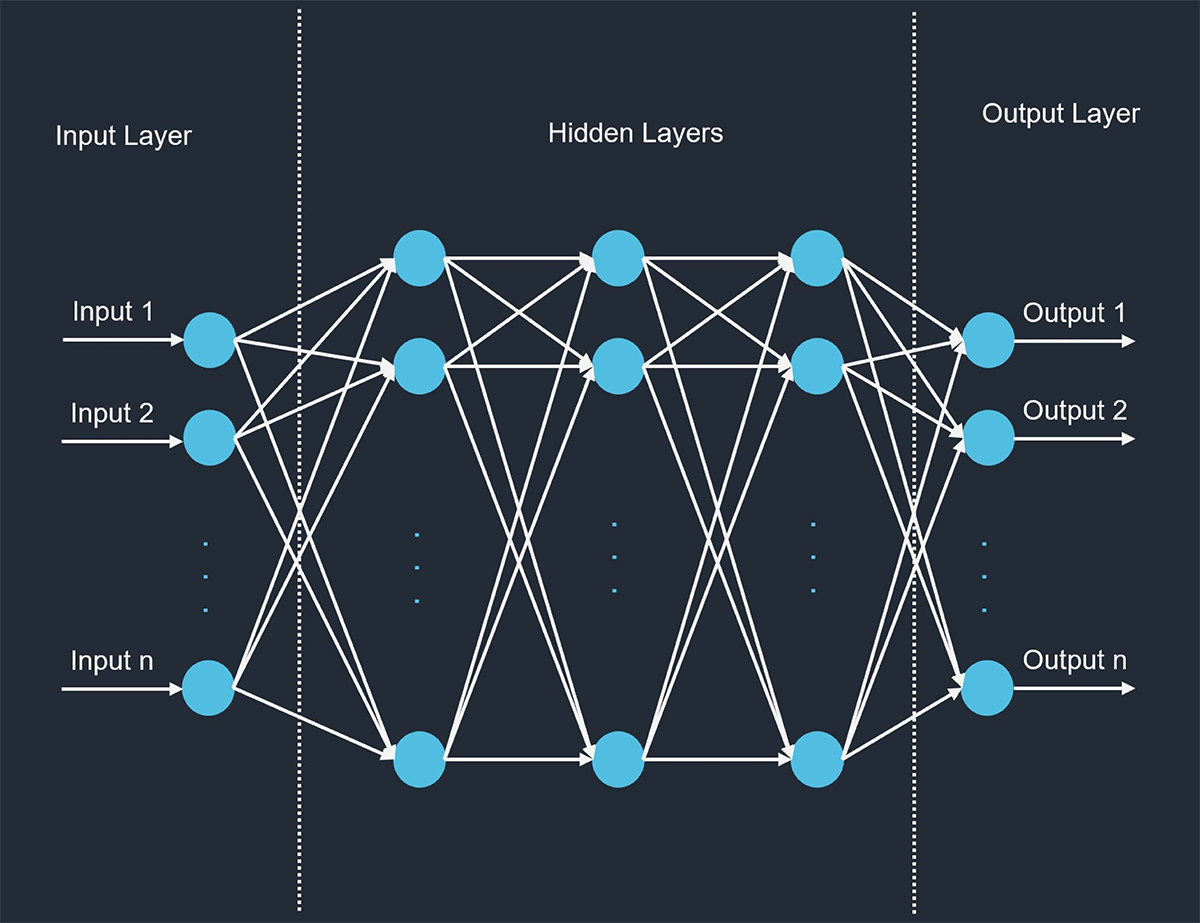
In NN models, the number of lines connecting the neurons represents the number of parameters in the model. As seen in Figure 1, there is no fixed relationship with the number of variables. The modeler is able to decide on the number of layers, the number of neurons in each layer, and how the neurons between each layer are related.
What is a large language model (LLM)?
An LLM, in short, is just a language model with tons of parameters and tons of training data. Among the famous LLMs developed by OpenAI, GPT-3 has 175 billion parameters, and GPT-3.5 (InstructGPT) has 1.3 billion parameters. It is worth noting that the output from InstructGPT is preferred to the output from GPT-3 in human evaluations,2 which demonstrates that bigger LLMs are not always better. The latest LLM released by OpenAI as of September 2023 is GPT-4, estimated to have 1 trillion parameters.3
The first AI language models can be traced back to 1966, so why are they being talked about so much recently? The game changer in language modeling is called transformers, a machine learning model architecture publicized in 2017.
What is embedding?
Before stepping into transformers, a key concept of language models is called embedding. To understand embeddings, it is important to understand tokenization, which is to split a sentence into a list of tokens. Tokens are similar to words, but usually one word can be split into more than one token. For example,
- To represent the word “dogs” we would use two tokens, one is “dog” and the second represents the plural form.
- To represent the word “microwave,” we could use two tokens of “micro” and “wave.”
Using tokens instead of words helps reduce the vocabulary needed in a language model.
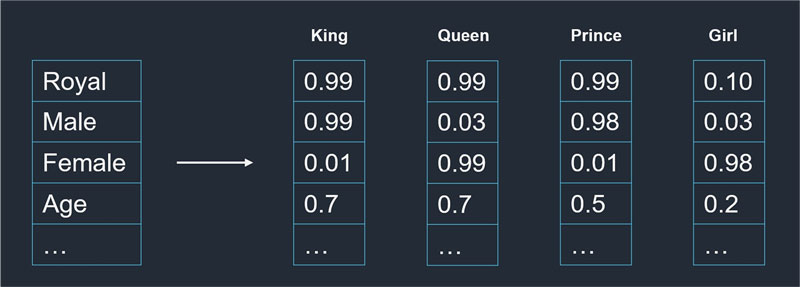
Embedding is the processing of representing tokens by vectors (lists of numbers), and it is often tens or hundreds of dimensions (entries in a vector). Figure 2 demonstrates this idea. For example, assume the first dimension of the embedded vectors represents “royal” and the words “king,” “queen,” and “prince” have high values (0.99) in the first dimension, while the word “girl” has a low value (0.10). One famous example of embedding analogies is "king" - "man" + "woman" = "queen." However, in practice, the modeler does not have control over what each dimension represents, which is shown in the first vector in Figure 2. Instead, the modeler would decide on the number of elements in each of the embedded vectors, then the embedding model will output the vector for each token.
Figure 2: Embedding Example
What is a transformer?
As noted earlier, a transformer is a machine learning architecture published in 2017 that accelerated language model advancement. It has become the foundation for natural language processing models.
The most innovative points of transformers are positional encoding and self-attention. Positional encoding is the vector representation of the position of the word in the sentence, and it is added to the token embedding and used as the input to the model. To understand self-attention, here is an example about the word “server” in two sentences representing different meanings:
- “Server, can I have the check?”
- “Looks like I just crashed the server.”
“Check” in the first sentence and “crashed” in the second are the key to understanding what “server” means. Self-attention is the process for the model to give different weights to each input word to recognize that “check” and “crashed” are important to understanding “server” correctly.
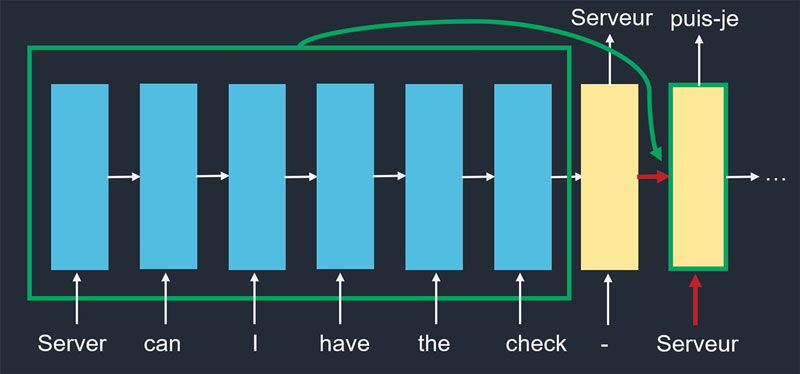
Figure 3 illustrates how a transformer works for translating English to French. The blue boxes represent the input embedding with the positional encoding added, one box for each token. The yellow boxes represent the output of the model. Now focus on the second yellow box. In language models before transformers, the inputs to the second yellow box are marked by red arrows. The first component is the word generated from the prior step, and this is the generated word in the chart. The second component is the output from the prior step. Imagine this as a vector summarizing the input and the first yellow box, but it is a hidden step not seen by the user. On the other hand, transformers give this yellow box additional information, which is the green arrow, representing access to the entire input. For each of the words in the output, self-attention gives a weight to each of the input words, takes the weighted average of them, and uses it in addition to the red arrows to decide on the next word.
Figure 3: How a Transformer Works
What is ChatGPT?
ChatGPT is the chatbot provided by OpenAI with GPT-3.5 or GPT-4 used as the backend model. As discussed, LLMs only predict the next token. In order to make the transition to a chatbot, supervised learning is needed by using labeled data to update the model parameters and allow the model to demonstrate the question-and-answer behavior. In addition, GPT-3.5 trained further on human-labeled rankings of model outputs, which helps the model to generate more human-sounding answers from a given question.
The importance of prompt engineering
What is prompt engineering?
Prompt engineering is the process of designing effective prompts to guide the responses of an LLM in performing specific tasks.
Two key concepts in prompt engineering, as discussed in the course “ChatGPT Prompt Engineering for Developers4” by Andrew Ng and Isa Fulford, is to (1) give clear and specific instructions, and (2) give the model “time to think.”
When applying the first concept—give clear and specific instructions—the user should also strive to make prompts concise. However, it’s important not to conflate “concise” with “short.” It should rather be devoid of unnecessary information. It is often highly effective to provide contextually rich and detailed prompts containing relevant background information, examples of solutions to similar problems, and instructions on the structure of the desired output. When using an LLM, the technique of providing an example as part of the prompt to demonstrate the desired output is called one-shot prompting. When more than one example is provided in the prompt, it is called few-shot prompting. We illustrate one-shot prompting in the image generation example Iteration 4 provided in Figure 7 below.
The second concept highlighted from Ng and Fulford is to give the model “time to think.” What is meant here is to provide a framework within the prompt that instructs the model to follow a logical reasoning process rather than jumping straight to the solution. This can be achieved by specifying the steps needed to complete the task and by instructing the model to find and provide the reasoning that allows it to reach its conclusion.
Structuring prompts using these concepts is an effective way to reduce hallucinations, i.e., statements that sound plausible but are not true. By instructing the model to first find relevant information or by providing the information directly within your prompt and then using that information to answer the question at hand in a logical manner, the potential of inaccurate model output is greatly reduced.
Lastly, it is important to remember that, while interactions with an LLM—especially in chatbot form—may seem conversational, the user is using natural language to program a computer to complete a task, or series of tasks. Take an iterative approach to prompting, and fine-tune inputs until the desired output is achieved.
To demonstrate the importance of prompt engineering, a series of images are shown below that are generated by Midjourney5 with similar but slightly different prompts.
Iteration 1: Use “Actuaries working” as the prompt. The images generated in Figure 4 are fascinating, but the content is not related to what actuaries really do.
Figure 4: Midjourney-Generated Image in Iteration 1

Iteration 2: To improve the output, we added more instructions (highlighted in orange) and changed the prompt to be “Actuaries working on a computer in an office.” The generated images in Figure 5 are more realistic than those based on Iteration 1 in Figure 4 but remain stylized representations of the day-to-day work done by today’s actuaries.
Figure 5: Midjourney-Generated Image in Iteration 2

Iteration 3: More details are added to the prompt (highlighted in green), specifying what needs to be shown on the computer screen. The “style raw” command is domain-specific to the Midjourney environment and highlights the concept that the user is in fact programming the computer using (near) natural language, and not just having a conversation with the computer. The updated prompt is “Actuaries working on spreadsheets on a computer in an office – style raw,” and the generated image is shown in Figure 6.
Figure 6: Midjourney-Generated Image in Iteration 3

Iteration 4: Through Iterations 1 to 3, we observed the bias of the model: the lack of diversity where no woman was depicted in the generated images. One-shot prompting is employed to attempt to correct this bias: a Milliman-licensed photo (shown in Figure 7) is added as an image prompt, along with the wording prompt from Iteration 3 “Actuaries working on spreadsheets on a computer in an office – style raw,” The updated output is shown in Figure 8, which finally represents female actuaries.
Figure 7: Image Prompt Used in Iteration 4

Figure 8: Midjourney-Generated Image in Iteration 4

Use cases for the insurance industry
Below, a few of the potential use cases for AI and LLMs for insurance practitioners are outlined. This list is no doubt incomplete, and this rapidly evolving technology will spur development, disruption, and innovation across the insurance industry and beyond.
Claims
AI has the potential to transform how insurers analyze claims. One of the important aspects of LLMs is their ability to convey the meaning of text and make that meaning searchable—this is what distinguishes LLMs from commonplace keyword searches or traditional text-mining approaches. Typically, claims are analyzed based on fields that have been predefined using a form filled in by claims handling staff. Freeform text fields that contain notes or other information are largely unused. LLMs can be used to summarize or categorize that information, even in a structured format, through effective prompts, categorizing and standardizing those fields' contents. That data can then be analyzed directly, using traditional techniques, or can be used in conjunction with other LLMs to allow for a chatbot-like experience, allowing users to ask questions and get answers back about that data.
Customer service
Staff can use AI to improve customer experience and increase efficiency. LLMs can be utilized to query a database of company-specific internal information, allowing staff to use AI-powered chatbots to answer questions and solve problems faster than in the past. Staff could be trained to ask the bot first before asking for help or escalating an issue to a supervisor. Additionally, the LLM could also be fed policy or claims information for a specific customer, so that answers from the bot are personalized for the customer and show how that information relates back to policy contracts or company policies. LLMs are not restricted to written work—they can even be built to work with audio and visual data, potentially opening the door to new products and services.
Analytics
Analytics will be made available to more users who may or may not have the technical training to perform the analyses. AI and LLMs are useful in that they retain the meaning of text and can be fed documents on which to base their outputs, but how does numeric data fit into this? Purpose-built LLMs can produce code, like structured query language (SQL), given a set of column names on which to build queries. Figure 9 shows a SQL example generated by ChatGPT (which cost about $0.0015 to produce). This example may be further extended by then executing the query on a database to get the appropriate answer and putting the result into a spreadsheet. AI and LLMs will allow even the average nontechnical user the ability to analyze data on a scale not available before. Of course, users should still understand the data and how to review the results for accuracy.
Figure 9: SQL Example Generated by ChatGPT
| Prompt | Result |
|---|---|
| I need help to write a SQL query that answers the following question: What are the top performing Eastern region segments in 2022 and how much did they grow since 2021? The columns in my table are: YEAR, QUARTER, REGION, SEGMENT, REVENUE, EXPENSES, EMPLOYEE COUNT, TERRITORY, MANAGER | SELECT t2022.REGION, t2022.SEGMENT, t2022.REVENUE - t2021.REVENUE AS GROWTH FROM your_table_name t2022 JOIN your_table_name t2021 ON t2022.REGION = t2021.REGION AND t2022.SEGMENT = t2021.SEGMENT WHERE t2022.YEAR = 2022 AND t2021.YEAR = 2021 AND t2022.REGION = 'Eastern' ORDER BY GROWTH DESC LIMIT 10; |
Risk management
Managing AI risk and mitigating potential issues should be a high priority for anyone looking to use the models and beyond. Testifying to Congress,6 Christina Montgomery, Chief Privacy and Trust Officer of IBM, cautioned that “the era of AI cannot be another era of move fast and break things” (a nod to Facebook founder Mark Zuckerberg’s famous motto) and that “reasonable policy and sound guardrails” are necessary. These calls for regulatory action were echoed that day by fellow congressional witnesses Sam Altman, CEO of OpenAI, and Gary Marcus, Professor Emeritus of New York University (NYU). Concurrently, all three witnesses urged Congress that regulation and risk management must be formed in a way that does not stifle innovation or cause the United States to miss out on the huge potential economic benefits that AI may bring. These same risk-reward considerations must be balanced by individuals and companies embracing AI for their own uses.
Users and developers of AI should have technological safeguards and containment strategies in place. As Mustafa Suleyman, cofounder of DeepMind, discusses, new technologies can have “emergent effects that are impossible to predict or control, including negative and unforeseen consequences.” He emphasizes that “containment is the overarching ability to control, limit, and, if need be, close down technologies at any stage of their development or deployment.”7 As AI progresses closer to artificial general intelligence (AGI)8, ensuring that human beings remain firmly in control of the tools and technologies we develop must remain a priority.
While it is impossible to list all current and future risks, it may be helpful to review their usage guidelines in the public and private sectors. Figure 10 summarizes restrictions on the usage of generative AI models and services from OpenAI and the table in Figure 11 summarizes guidelines and principles on their usage from the National Institute of Standards and Technology (NIST).
Figure 10: OpenAI Disallowed Usage of Models9
OpenAI’s models may not be used for the following activities:
|
OpenAI, and virtually all companies providing AI services, specifically ban illegal activities as well as activities that may enable illegal behavior or other harmful outcomes. However, there are other open-source technologies available that can be run on a person’s local machine whose usage will be much more difficult to track and may be used for illegal activities. For example, hacker groups may use LLMs privately to create malware and execute phishing attacks that are harder to defeat because they appear legitimate.
Figure 11: NIST AI Risk Management Framework10
NIST defines a trustworthy AI as including the following characteristics:
|
The NIST’s AI Risk Management Framework has been referenced by public institutions such as the University of Wisconsin, Madison, and Washington state’s Office of the Chief Information Officer (CIO),12 where the generative AI models in use by those institutions should adhere to the framework. The federal government is also advocating for the AI Risk Management Framework and other important measures meant to promote the responsible use and innovation of generative AI.13 The framework is useful for anyone considering using LLMs but would be especially useful within law enforcement, where bias is a significant concern, because the framework calls out that the models should be thoroughly tested and understood before being deployed.
Additionally, Cambridge University Press clearly states that “AI use must be declared and clearly explained in publications” in their authorship and contributorship policies.14 This is a common requirement found in multiple other policies specifically targeting generative AI but it is also a guideline promulgated by the Actuarial Standards Board in Actuarial Standard of Practice No. 56 – Modeling,15 which covers the uses of models in general. Strong support from the public and private sectors on the ethical and safe usage of generative AI is paramount in ensuring that these models are deployed responsibly. While it is still possible for bad actors to use them for harm, getting started on the right foot is an important step as the models become more ubiquitous.
Closing
With the accessibility of AI being vast and the cost of its use relatively low, it’s clear why so many people are now talking about a technology that has been around in some form for decades. There are clear benefits to its use, including increased efficiency and accuracy when analyzing text data, the ability for users to express commands in natural language and have the machine interpret and respond in a conversation-like manner, and aiding with tasks where context is important, like writing computer code. Through proper training and evaluation of the possible risks associated with its use, AI and LLMs have the potential to disrupt and drastically improve operations within the insurance industry.
1UBS Global (February 23, 2023). Let's chat about ChatGPT. Retrieved October 1, 2023, from https://www.ubs.com/global/en/wealth-management/our-approach/marketnews/article.1585717.html.
2Ouyang, L. et al. (2022). Training language models to follow instructions with human feedback. ArXiv:2203.02155. Retrieved October 1, 2023, from https://arxiv.org/pdf/2203.02155.pdf.
3Kerner, S.M. Large Language Models (LLMs). WhatIs.com: TechTarget. Retrieved October 1, 2023, from https://www.techtarget.com/whatis/definition/large-language-model-LLM.
4DeepLearning.AI. Short course: ChatGPT Prompt Engineering for Developers. Retrieved October 1, 2023, from https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/.
5See https://www.midjourney.com/home/?callbackUrl=%2Fapp%2F%29%2F.
6U.S. Senate Judiciary Committee Subcommittee on Privacy, Technology, and the Law (May 16, 2023). Subcommittee Hearing: Oversight of AI: Rules for Artificial Intelligence.” Retrieved October 1, 2023, from https://www.judiciary.senate.gov/committee-activity/hearings/oversight-of-ai-rules-for-artificial-intelligence.
7Suleyman, Mustafa. The Coming Wave. Retrieved October 1, 2023, from https://www.the-coming-wave.com/.
8Artificial general intelligence, or AGI, is broadly defined as self-aware AI that can think, adapt, and could learn to perform any task as well or better than a human.
9OpenAI (March 23, 2023). Usage Policies. Retrieved October 1, 2023, from https://openai.com/policies/usage-policies.
10NIST. AI Risk Management Framework. Retrieved October 1, 2023, from https://www.nist.gov/itl/ai-risk-management-framework.
11UW-Madison Information Technology (July 26, 2023). Generative AI @ UW–Madison: Use and Policies. Retrieved October 1, 2023, from https://it.wisc.edu/generative-ai-uw-madison-use-policies/.
12Washington State Office of the CIO (August 8, 2023). Interim Guidelines for Purposeful and Responsible Use of Generative AI in Washington State Government. Retrieved October 1, 2023, from https://ocio.wa.gov/policy/generative-ai-guidelines.
13White House (May 4, 2023). Fact Sheet: Biden-Harris Administration Announces New Actions to Promote Responsible AI Innovation That Protects Americans’ Rights and Safety. Retrieved October 1, 2023, from https://www.whitehouse.gov/briefing-room/statements-releases/2023/05/04/fact-sheet-biden-harris-administration-announces-new-actions-to-promote-responsible-ai-innovation-that-protects-americans-rights-and-safety/.
14Cambridge University Press. Authorship and Contributorship. Retrieved October 1, 2023, from https://www.cambridge.org/core/services/authors/publishing-ethics/research-publishing-ethics-guidelines-for-journals/authorship-and-contributorship.
15Actuarial Standards Board (December 2019). Actuarial Standard of Practice No. 56: Modeling. Retrieved October 1, 2023, from http://www.actuarialstandardsboard.org/asops/modeling-3/.